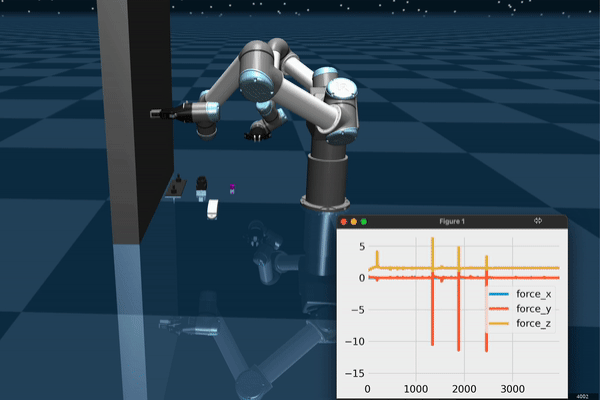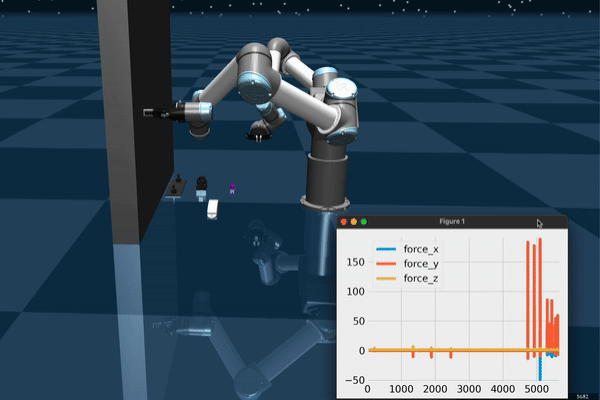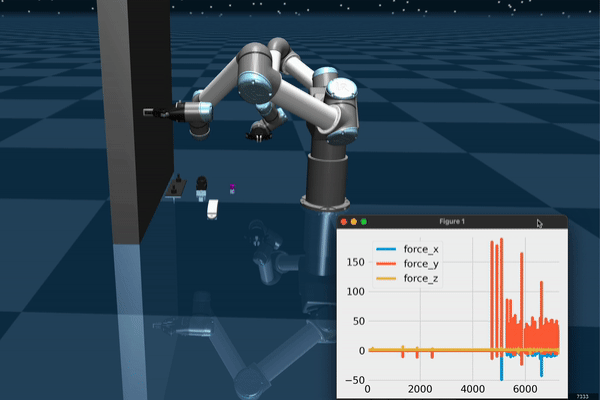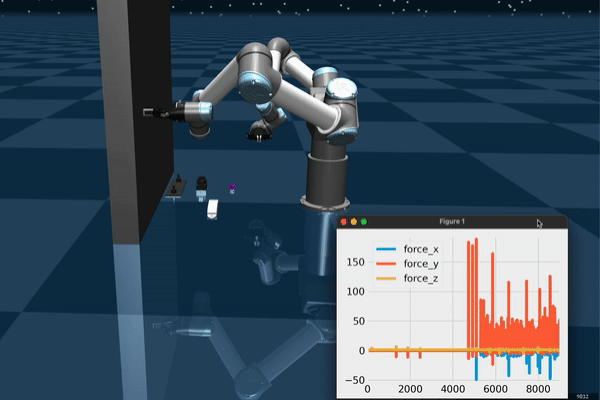
Data Collection and Teleoperation

The user teleoperates the robot for picking up objects in the scene. PS Move controllers allow for opening/closing the gripper and selecting a target which the robot moves to when the trigger is pressed. This setup can be used for collecting expert demonstrations, especially if the task is not sufficiently difficult.